Adaptive Traffic Profiles as a tool to model heterogeneous systems in gem5
Heterogeneous systems, composed of a variety of devices, are especially difficult to design and dimension for target use-cases. There is a pressing need for tools that can facilitate the exploration of their design space, so that designers and testers can be allowed to predict or measure performance on their target use-cases. On the other hand, a new generation of applications, such as automated driving or Industry 4.0 ones, is putting challenging requirements on heterogeneous systems. These applications are time critical, meaning that firm upper bounds on their execution time must be guaranteed a priori, or they will endanger the safety and property of human beings.
To satisfy both the above requirements, Arm has recently released the AMBA Adaptive Traffic Profiles (ATP) framework as an open-source reference implementation. ATP are a portable way to generate input for the verification and/or design space exploration of heterogeneous systems. ATP emulate the traffic injection pattern of masters in a heterogeneous system, e.g., a GPU accessing a range of consecutive RAM addresses, via a simple rule-based syntax. ATP applications can run in both standalone mode, with ATP masters communicating with ATP slaves, or in mixed-mode, with a host platform, such as the gem5 simulator, acting as a traffic forwarder. We present the basics of ATP syntax and capabilities, and then we show how we used the latter, together with gem5, to design quasi worst-case scenarios for a First-Ready, First-Come-First-Served (FR-FCFS) DRAM controller. This allows us to benchmark the results of an analytical technique to compute upper bounds on the worst-case delay (WCD) of the same system: by comparing the (possibly pessimistic) analytical upper bounds to the results obtained using a gem5 simulation fed by ATP profiles, we can bound the pessimism of the analytical technique.
ATP are a synthetic traffic modelling framework, representing a device executing a workload. A Master ATP models what a master (e.g., a GPU) would do, i.e. send memory requests and receive responses, according to configurable timing properties (e.g., a new request every 100 ns) and target addresses. Its counterpart is the Slave ATP, which models what a slave (e.g., a memory) would do, i.e. respond to requests according to a fixed latency and bandwidth. Both can have a limit of outstanding transactions, after which they become locked, i.e., unable to continue their execution according to the configured timing. An ATP reverts to its active state when the outstanding transactions are again below the limit (e.g., because a slave has responded to a master’s request).
![]()
Figure 1.
The basic building block of an ATP is the ATP FIFO. These can be composed to form complex behaviors in pretty much the same way basic harmonics can compose complex waveforms. An ATP FIFO is a queue with its own size and rate. A write FIFO models a producer, and a read FIFO models a consumer. In a write FIFO, memory-request operations fill the buffer up to its size, and memory responses instead drain it. If a buffer overrun occurs, the event is logged and the corresponding profile is locked. A read FIFO is the dual of the write one and behaves very similarly: its rate is a depletion rate, i.e., the rate at which information is consumed. An additional parameter, TxnLimit, can be set to limit the number of in-flight transactions at any given time. ATP FIFOs are associated with a pattern, describing how the address and data size fields of transactions are to be filled. An ATP FIFO Profile element groups together a FIFO and a pattern object into a self-contained descriptor, and assigns it to a system device master, as shown in the example. In this example the FIFO will generate a maximum of 1000 read requests at a rate of 1GB/s, the requests will be 64B long with the address incrementing by 64 each time. The latency tolerance is approximately (FIFO size - packet size)/Rate = 1.85 us.
The AMBA ATP framework comes with its own platform-independent engine that can be plugged into event- or time-driven modelling, simulation and testing platforms. ATP already includes a gem5 adaptor layer, hence it can be integrated with gem5 without any effort by users. The gem5 adaptor ProfileGen is implemented as a MemObject derived class, which allows gem5 to send and receive memory request and response packets from the ATP engine. ProfileGen connects to other gem5 objects by instantiating a configurable number of master ports dedicated to individual ATP masters, through which it sends and receives packets coming from/destined to such masters.
As anticipated, we use ATP and gem5 to try to maximize the access delay at a FR-FCFS DRAM controller, shown in the figure below. In particular we want to obtain an estimate of the maximum delay that a read request may suffer, as a function of its position in the controller’s read queue. Read requests can be either hits or misses. The latter need to “open the row” before accessing DRAM cells, hence incurring additional delays. The former do not, hence are given priority to maximize efficiency - hence the “First-ready” name. Miss read requests are instead scheduled FCFS. Write requests are queued separately, and the write queue is served when above its watermark W. When in write mode, the controller serves a batch of N_wd writes consecutively before switching back to serving reads. Lastly, periodic DRAM refreshes occur, to avoid loss of data. Assuming that: a) the number of read-hit overtakes is upper bounded by a known limit, call it N_cap (without which the WCD of a read-miss would be unbounded), and b) the arrival rate at the write queue is upper bounded, we can compute an upper bound on the WCD by describing the controller as a Finite-State Machine, where states are operations and transitions are their scheduling time costs, and bounding from above the time cost of any path that leads to the N-th read miss. This technique is described in more detail in the following paper: M. Andreozzi, F. Conboy, G. Stea, R. Zippo, “Heterogeneous systems modelling with Adaptive Traffic Profiles and its application to worst-case analysis of a DRAM controller”, Proc. of IEEE COMPSAC 2020, July 2020.
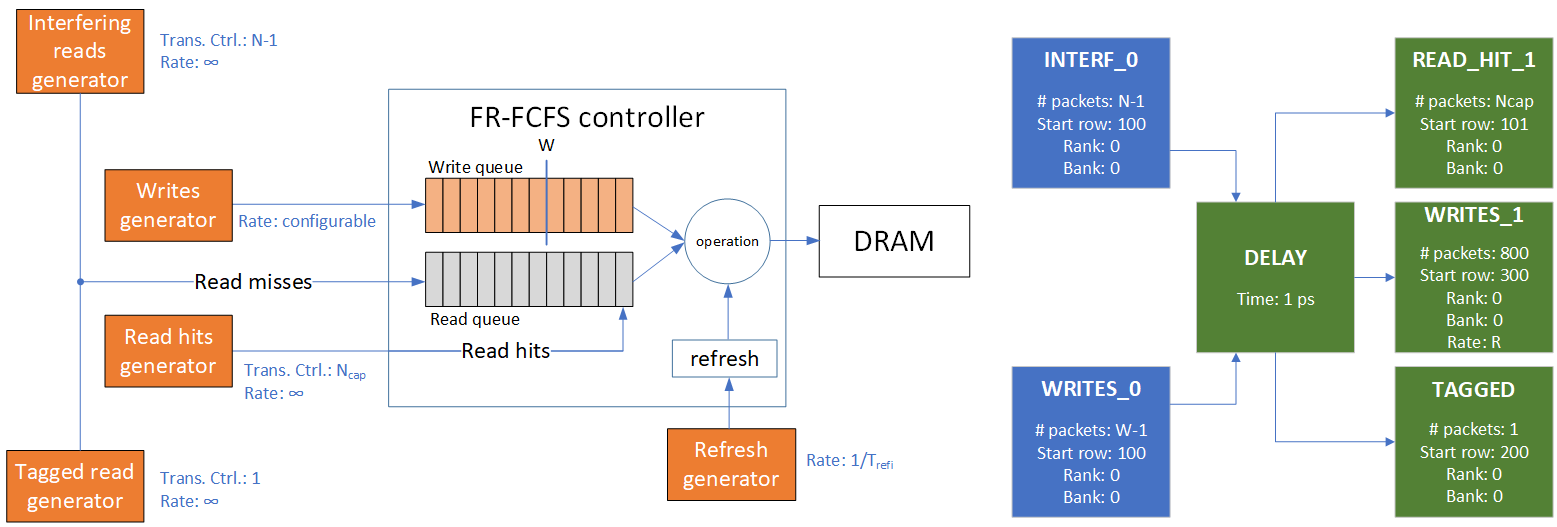
Figure 2.
The above upper bound could in principle be pessimistic, due to several assumptions that are required to make it computable in practice. To benchmark it, we simulate the above system using gem5. In the simulative approach, ATP FIFOs are used as input to a modified gem5 model of a DRAM memory device and controller to setup a quasi-worst-case scenario, shown in Fig. 2. The gem5 model includes a locking mechanism, that halts the service of requests until there are the N-1 enqueued, and a refresh which is activated at least once in the scenario. The ATP FIFOs that we used are shown at the right of the same figure. The setup profiles (in blue) produce the packets that fill up the read and write queues to create suitable initial conditions, i.e., N-1 read-misses in the read queue and W-1 write-misses in the write queue. Run profiles (in green) are used to produce the N-th memory request (upon receiving which the controller will start to serve requests), the N_cap read-hits that will overtake it, and the writes that keep arriving during the simulation at the configured rate. The simulation stops after the N-th read has been served.
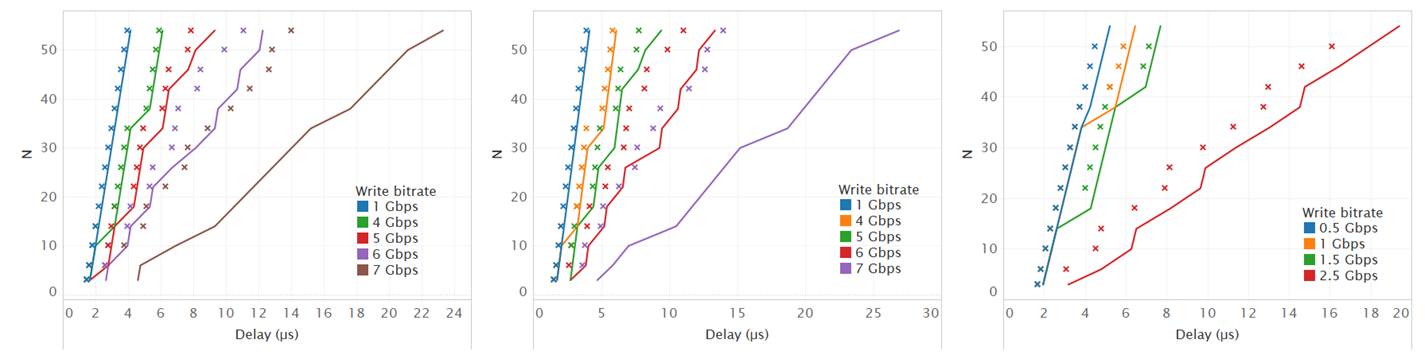
Figure 3.
We simulate three memory configurations: a DDR3-1600, a DDR4-2400, and an LPDDR-3200 based on a 4Gbit per channel datasheet. All use an open-adaptive page management policy and Row-Rank-Bank-Column-Channel address mapping. Experiments were run using values of N between 2 and 55, and the write request rate was varied from 1 to 8 Gbps. The figure reports the lower and upper bounds on the WCD for the three above-mentioned technologies (DDR3 left, DDR4 center, LPDDR right). All show that gem5 simulations are very close to the upper bounds until the write request rate gets high (i.e., 6 Gbps for DDR3/4, 2.5 Gbps for LPDDR). The increased distance at high write rates may be due to both pessimism in the upper bound, or the fact that the simulation model loses accuracy in these cases.