
last edited: 2024-04-16 17:50:15 +0000
CHI
The CHI ruby protocol provides a single cache controller that can be reused at multiple levels of the cache hierarchy and configured to model multiple instances of MESI and MOESI cache coherency protocols. This implementation is based of Arm’s AMBA 5 CHI specification and provides a scalable framework for the design space exploration of large SoC designs.
CHI overview and terminology
CHI (Coherent Hub Interface) provides a component architecture and transaction-level specification to model MESI and MOESI cache coherency. CHI defines three main components as shown in the figure below:
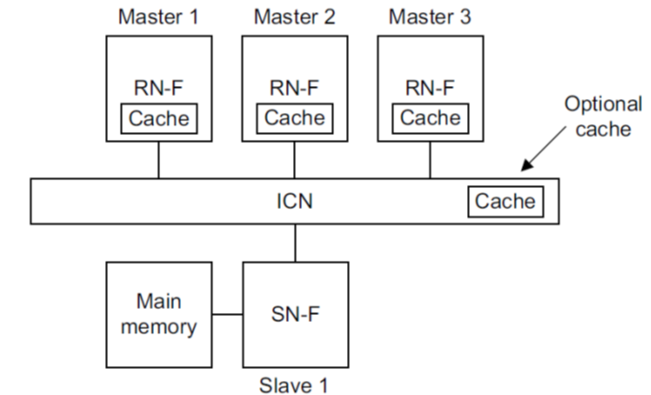
- the request node initiates transactions and sends requests towards memory. A request node can be a fully coherent request node (RNF), meaning the request node caches data locally and should respond to snoop requests.
- the interconnect (ICN) which is the responder for request nodes. At protocol level the interconnect is a component encapsulating the fully coherent home nodes (HNF) of the system.
- the slave nodes (SNF), which interface with the memory controllers.
An HNF is the point of coherency (PoC) and point of serialization (PoS) for a specific address range. The HNF is responsible for issuing any required snoop requests to RNFs or memory access requests to SNFs in order to complete a transaction. The HNF can also encapsulate a shared last-level cache and include a directory for targeted snoops.
The CHI specification also defines specific types of nodes for non-coherent requesters (RNI) and non-coherent address ranges (HNI and SNI), e.g., memory ranges belonging to IO components. In Ruby, IO accesses don’t go though the cache coherency protocol so only CHI’s fully coherent node types are implemented. In this documentation we interchangeably use the terms RN / RNF, HN / HNF, and SN/SNF. We also use the terms upstream and downstream to refer to components in the previous (i.e. towards the cpu) and next (i.e. towards memory) levels in the memory hierarchy, respectively.
Protocol overview
The CHI protocol implementation consists mainly of two controllers:
Memory_Controller(src/mem/ruby/protocol/chi/CHI-mem.sm) implements a CHI slave node. It receives memory read or write requests from the home nodes and interfaces with gem5’s classic memory controllers.Cache_Controller(src/mem/ruby/protocol/chi/CHI-cache.sm) generic cache controller state machine.
In order to allow fully flexible cache hierarchies, Cache_Controller can be configured to model any cache level (e.g. L1D, priv. L2, shared L3) within both request and home nodes. Furthermore it also supports multiple features not available in other Ruby protocols:
- configurable cache block allocation and deallocation policies for each request type.
- unified or separate transaction buffers for incoming and outgoing requests.
- MESI or MOESI operation.
- directory and cache tag and data array stalls.
- parameters to inject latency in multiple steps of the request handling flow. This allows us to more closely calibrate the performance.
The implementation defines the following cache states:
I: line is invalidSC: line is shared and cleanUC: line is exclusive/unique and cleanSD: line is shared and dirtyUD: line exclusive/unique and dirtyUD_T:UDwith timeout. When a store conditional fails and causes the line to transition from I to UD, we transition toUD_Tinstead if the number of failures is above a certain threshold (configuration defined). InUD_Tthe line cannot be evicted from the requester for a given number of cycles (also configuration defined); after which the lines goes to UD. This is necessary to avoid livelocks in certain scenarios.
The figure below gives an overview of the state transitions when the controller is configured as a L1 cache:

Transitions are annotated with the incoming request from the cpu (or generated internally, e.g. Replacements) and the resulting outgoing request sent downstream. For simplicity, the figure omits requests that do not change states (e.g., cache hits) and invalidating snoops (final state is always I). For simplicity, it also shows only the typical state transitions in a MOESI protocol. In CHI the final state will ultimately be determined by the type of data returned by the responder (e.g., requester may receive UD or UC data in response to a ReadShared).
The figures below show the transition for a intermediate-level cache controller (e.g., priv. L2, shared L3, HNF, etc):


As in the previous case, cache hits are omitted for simplicity. In addition to the cache states, the following directory states are defined to track lines present in an upstream cache:
RU:an upstream requester has line in UC or UDRSC: one or more upstream requesters have line in SCRSD: one upstream requester has line in SD; others may have it in SCRUSC:RSC+ current domain stills has exclusive accessRUSD:RSD+ current domain stills has exclusive access
When the line is present both in the local cache and upstream caches the following combined states are possible:
UD_RSC,SD_RSC,UC_RSC,SC_RSCUD_RU,UC_RUUD_RSD,SD_RSD
The RUSC and RUSD states (omitted in the figures above) are used to keep track of lines for which the controller still has exclusive access permissions without having it in it’s local cache. This is possible in a non-inclusive cache where a local block can be deallocated without back-invalidating upstream copies.
When a cache controller is a HNF (home node), the state transactions are basically the same as a intermediate level cache, except for these differences:
- A
ReadNoSnpis sent to obtain data from downstream, as the only downstream components are the SNs (slave nodes). - On a cache and directory miss, DMT (direct memory transfer) is used if enabled.
- On a cache miss and directory hit, DCT (direct cache transfer) is used if enabled.
For more information on DCT and DMT transactions, see Sections 1.7 and 2.3.1 in the CHI specification. DMT and DCT are CHI features that allow the data source for a request to send data directly to the original requester. On a DMT request, the SN sends data directly to the RN (instead of sending first to the HN, which would then forwards to the RN), while with DCT, the HN requests that a RN being snooped (the snoopee) to send a copy of the line directly the original requester. With DCT enabled, the HN may also request that the snoopee to send the data to both the HN and the original requester, so the HN can also cache the data. This depends on the allocation policy defined by the configuration parameters. Notice that the allocation policy also changes the cache state transitions. For simplicity, the figure above illustrates an inclusive cache.
The following is a list of the main configuration parameters of the cache controller that affect the protocol behavior (please refer to the protocol SLICC specification for details and a full list of parameters)
downstream_destinations: defines the destinations for requests sent downstream and is used to build the cache hierarchy. Refer to thecreate_systemfunction inconfigs/ruby/CHI.pyfor an example of how to setup a system with private L1I, L1D and L2 caches for each core.is_HN: Set when the controller is used as a home node and point of coherency for an address range. Must be false for every other cache level.enable_DMTandenable_DCT: when the controller is a home node, this enables direct memory transfers and direct cache transfers for incoming read requests.allow_SD: allow the shared dirty state. This switches between MOESI and MESI operation.alloc_on_readshared,alloc_on_readunique, andalloc_on_readonce: whether or not to allocate a cache block to store data used to respond to the corresponding read request.alloc_on_writeback: whether or not to allocate a cache block to store data received from a writeback request.dealloc_on_uniqueanddealloc_on_shared: deallocate the local cache block if the line becomes unique or shared in an upstream cache.dealloc_backinv_uniqueanddealloc_backinv_shared: if a local cache block is deallocated due to a replacement, also invalidates any unique or shared copy of the line in upstream caches.number_of_TBEs,number_of_snoop_TBEs, andnumber_of_repl_TBEs: number of entries in the TBE tables for incoming requests, incoming snoops, and replacements.unify_repl_TBEs: replacements use the same TBE slot as the request that triggered it. In this casenumber_of_repl_TBEsis ignored.
These parameters affect the cache controller performance:
read_hit_latencyandread_miss_latency: pipeline latencies for a read request thar hits or misses in the local cache, respectively.snoop_latency: pipeline latency for an incoming snoop.write_fe_latencyandwrite_be_latency: front-end and back-end pipeline latencies for handling write requests. Front-end latency is applied between sending the acknowledgement response and the next action to be taken. Back-end is applied to the requester between receiving the acknowledgement and sending the write data.allocation_latency: latency between TBE allocation and transaction initialization.cache:CacheMemoryattached to this controller includes parameters such as size, associativity, tag and data latency, and number of banks.
Section Protocol implementation gives an overview of the protocol implementation while Section Supported CHI transactions describe the implemented subset of the the AMBA 5 CHI spec. The next sections refer to specific files in the protocol source code and include SLICC snippets of the protocol. Some snippets where slightly simplified compared to the actual SLICC specification.
Protocol implementation
The Figure below gives an overview of the cache controller implementation.
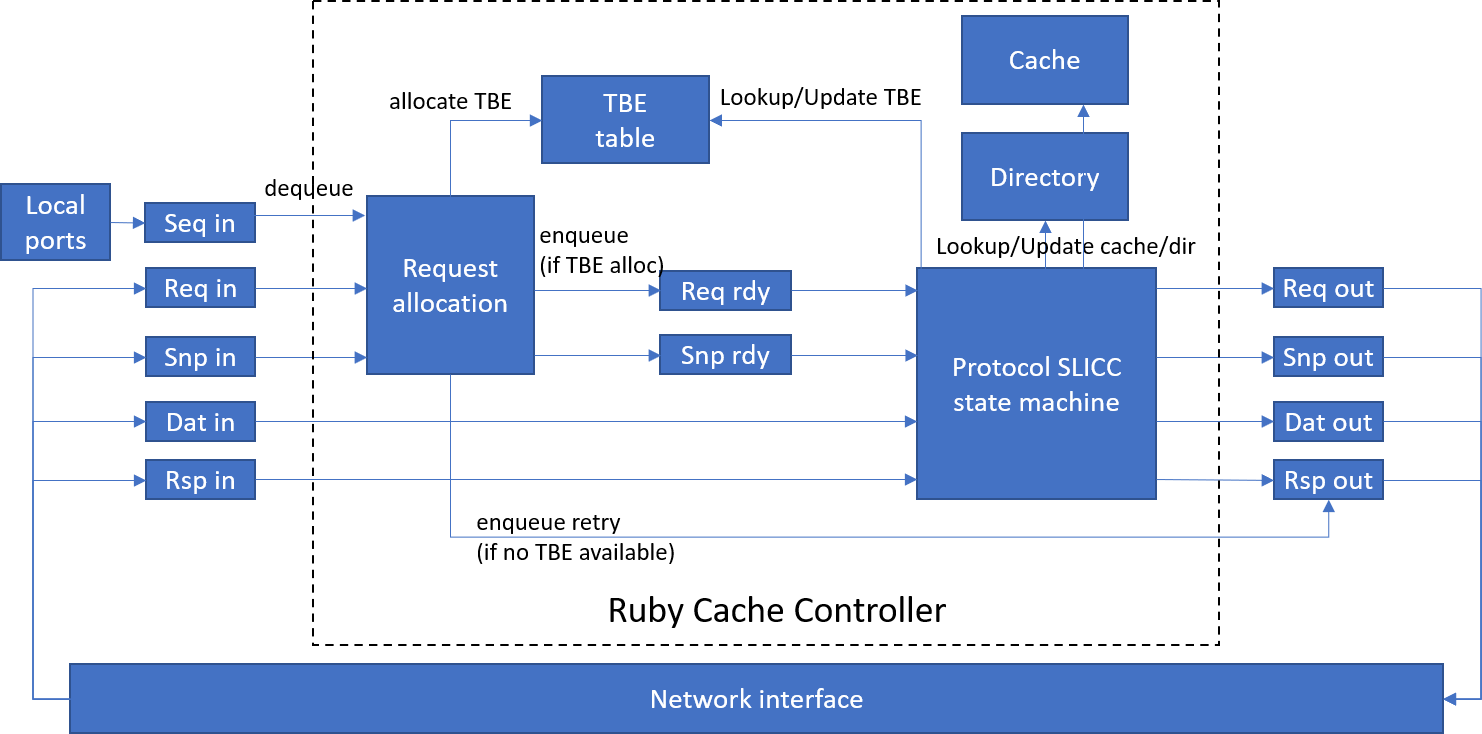
In Ruby, a cache controller is implemented by defining a state machine using SLICC language. Transitions in the state machine are triggered by messages arriving at input queues. On our particular implementation, separate incoming and outgoing messages queues are defined for each CHI channel. Incoming request and snoop messages that start a new transaction go through the same Request allocation process, where we allocate a transaction buffer entry (TBE) and move the request or snoop to an internal queue of transactions that are ready to be initiated. If the transaction buffer is full, the request is rejected and a retry message is sent.
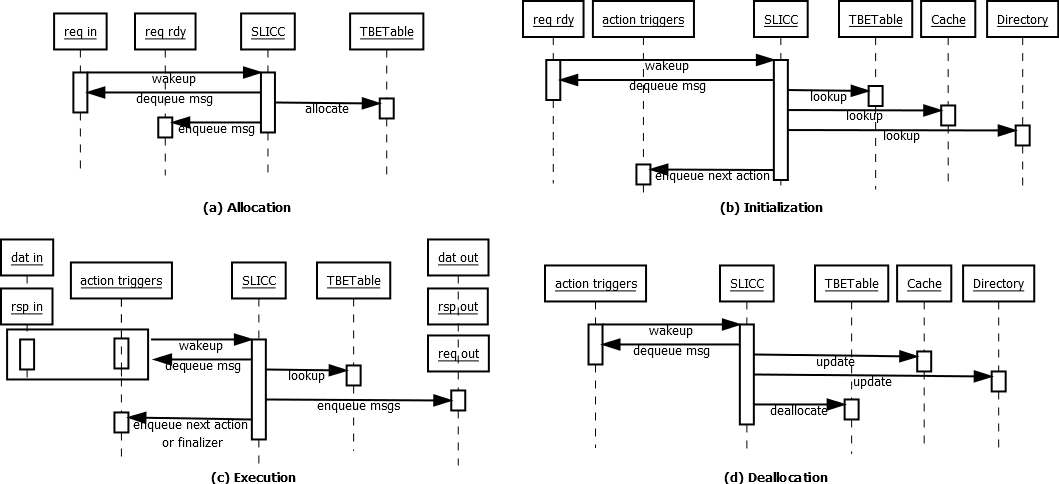
The actions to be performed for a message dequeued from the input / rdy queues depends on the state of the target cache line. The data state of the line is stored in the cache if the line is cached locally, while the directory state is stored in a directory entry if the line is present in any upstream cache. For lines with outstanding requests, the transient state is kept in the TBE and copied back to the cache and/or directory when the transaction finishes. The figure below describes the phases in the transaction lifetime and the interactions between the main components in the cache controller (input/output ports, TBETable, Cache, Directory and the SLICC state machine). The phases are described in more details in the subsequent sections.
Transaction allocation
The code snippet below shows how an incoming request in the reqIn port is handled. The reqIn port receives incoming messages from CHI’s request channel:
in_port(reqInPort, CHIRequestMsg, reqIn) {
if (reqInPort.isReady(clockEdge())) {
peek(reqInPort, CHIRequestMsg) {
if (in_msg.allowRetry) {
trigger(Event:AllocRequest, in_msg.addr,
getCacheEntry(in_msg.addr), getCurrentActiveTBE(in_msg.addr));
} else {
trigger(Event:AllocRequestWithCredit, in_msg.addr,
getCacheEntry(in_msg.addr), getCurrentActiveTBE(in_msg.addr));
}
}
}
}
The allowRetry field indicates messages that can be retried. Requests that cannot be retried are only sent by a requester that previously received credit (see RetryAck and PCrdGrant in the CHI specification). The transition triggered by Event:AllocRequest or Event:AllocRequestWithCredit executes a single action which either reserves space in the TBE table for the request and moves it to the reqRdy queue, or sends a RetryAck message):
action(AllocateTBE_Request) {
if (storTBEs.areNSlotsAvailable(1)) {
// reserve a slot for this request
storTBEs.incrementReserved();
// Move request to rdy queue
peek(reqInPort, CHIRequestMsg) {
enqueue(reqRdyOutPort, CHIRequestMsg, allocation_latency) {
out_msg := in_msg;
}
}
} else {
// we don't have resources to track this request; enqueue a retry
peek(reqInPort, CHIRequestMsg) {
enqueue(retryTriggerOutPort, RetryTriggerMsg, 0) {
out_msg.addr := in_msg.addr;
out_msg.event := Event:SendRetryAck;
out_msg.retryDest := in_msg.requestor;
retryQueue.emplace(in_msg.addr,in_msg.requestor);
}
}
}
reqInPort.dequeue(clockEdge());
}
Notice we don’t create and send a RetryAck message directly from this action. Instead we create a separate trigger event in the internal retryTrigger queue. This is necessary to prevent resource stalls from halting this action. Section Performance modeling below explains resource stalls in more details.
Incoming request from a Sequencer object (typically connected to a CPU when the controller is used as a L1 cache) and snoop requests arrive through the seqIn and snpIn ports and are handled similarly, except for:
- they do not support retries. If there are no TBEs available, a resource stall is generated and we try again next cycle.
- snoops allocate TBEs from a separate TBETable to avoid deadlocks.
Transaction initialization
Once a request has been allocated a TBE and moved to the reqRdy queue, an event is triggered to initiate the transaction. We trigger a different event for each different request type:
in_port(reqRdyPort, CHIRequestMsg, reqRdy) {
if (reqRdyPort.isReady(clockEdge())) {
peek(reqRdyPort, CHIRequestMsg) {
CacheEntry cache_entry := getCacheEntry(in_msg.addr);
TBE tbe := getCurrentActiveTBE(in_msg.addr);
trigger(reqToEvent(in_msg.type), in_msg.addr, cache_entry, tbe);
}
}
}
Each request requires different initialization actions depending on the initial state of the line. To illustrate this processes, let’s use as example a ReadShared request for a line in the SC_RSC state (shared
clean in local cache and shared clean in an upstream cache):
transition(SC_RSC, ReadShared, BUSY_BLKD) {
Initiate_Request;
Initiate_ReadShared_Hit;
Profile_Hit;
Pop_ReqRdyQueue;
ProcessNextState;
}
Initiate_Requestinitializes the allocated TBE. This actions copies any state and data allocated in the local cache and directory to the TBE.Initiate_ReadShared_Hitsets-up the set of actions that need to be executed to complete this specific request (see below).Profile_Hitupdates cache statistics.Pop_ReqRdyQueueremoves request message form thereqRdyqueue.ProcessNextStateexecutes the next action defined byInitiate_ReadShared_Hit.
Initiate_ReadShared_Hit is defined as follows:
action(Initiate_ReadShared_Hit) {
tbe.actions.push(Event:TagArrayRead);
tbe.actions.push(Event:ReadHitPipe);
tbe.actions.push(Event:DataArrayRead);
tbe.actions.push(Event:SendCompData);
tbe.actions.push(Event:WaitCompAck);
tbe.actions.pushNB(Event:TagArrayWrite);
}
tbe.actions stores the list of events that need to be triggered in order to complete an action. In this particular case, TagArrayRead, ReadHitPipe, and DataArrayRead introduces delays to model the cache
controller pipeline latency and reading the cache/directory tag array and cache data array (see Section Performance modeling). SendCompData sets-up and sends the data responses for the ReadShared request and WaitCompAck sets-up the TBE to expect the completion acknowledgement from the requester. Finally, TagArrayWrite introduces the delay of updating the directory state to track the new sharer.
Transaction execution
After initialization, the line will transition to the BUSY_BLKD state as show in transition(SC_RSC, ReadShared, BUSY_BLKD). BUSY_BLKD is a transient state indicating the line has now an outstanding transaction. In this state, the transaction is driven either by incoming response messages in the rspIn and datIn ports or trigger events defined in tbe.actions.
The ProcessNextState action is responsible for checking tbe.actions and enqueuing trigger event messages into actionTriggers at the end of all transitions to the BUSY_BLKD state. ProcessNextState first checks for pending response messages. If there are no pending messages, it enqueues a message to actionTriggers in order to trigger the the event at the head of tbe.actions. If there are pending responses, then ProcessNextState does nothing as the transaction will proceed once all expected responses are received.
Pending responses are tracked by the expected_req_resp and expected_snp_resp fields in the TBE. For instance, the ExpectCompAck action, executed from the transition triggered by WaitCompAck, is defined as follows:
action(ExpectCompAck) {
tbe.expected_req_resp.addExpectedRespType(CHIResponseType:CompAck);
tbe.expected_req_resp.addExpectedCount(1);
}
This causes the transaction to wait until a CompAck response is received.
Some actions can be allowed to execute when the transaction has pending responses. This actions are enqueued using tbe.actions.pushNB (i.e., push / non-blocking). In the example above tbe.actions.pushNB(Event:TagArrayWrite) models a tag write being performed while the transactions waits for the CompAck response.
Transaction finalization
The transaction ends when it has no more pending responses and tbe.actions is empty. ProcessNextState checks for this condition and enqueues a “finalizer” trigger message into actionTriggers. When handling this event, the current cache line state and sharing/ownership information determines the final stable state of the line. Data and state information are updated in the cache and directory, if necessary, and the TBE is deallocated.
Hazard handling
Each controller allows only one active transaction per cache line. If a new request or snoop arrives while the cache line is in a transient state, this creates a hazard as defined in the CHI standard. We handle hazards as follows:
Request hazards: a TBE is allocated as described previously, but the new transaction initialization is delayed until the current transaction finishes and the line is back to a stable state. This is done by moving
the request message from reqRdy to a separate stall buffer. All stalled messages are added back to reqRdy when the current transaction finishes and are handled in their original order of arrival.
Snoop hazards: the CHI spec does not allow snoops to be stalled by an existing request. If a transaction is waiting on a response for a request sent downstream (e.g. we sent a ReadShared and are waiting for
the data response) we must accept and handle the snoop. The snoop can be stalled only if the request has already been accepted by the responder and is guaranteed to complete (e.g. a ReadShared with pending data but
already acked with a RespSepData response). To distinguish between these conditions we use the BUSY_INTR transient state.
BUSY_INTR indicates the transaction can be interrupted by a snoop. When a snoop arrives for a line in this state, a snoop TBE is allocated as described previously and its state is initialized based on the currently active TBE. The snoop TBE then becomes the currently active TBE. Any cache state and sharing/ownership changes caused by snoop are copied back to the original TBE before deallocating the snoop. When a snoop arrives for a line in BUSY_BLKD state, we stall the snoop until the current transaction either finishes or transitions to BUSY_INTR.
Performance modeling
As described previously, the cache line state is known immediately when a transaction is initialized and the cache line can be read and written without any latency. This makes it easier to implement the functional
aspects of the protocol. To model timing we use explicit actions to introduce latency to a transaction. For example, in the ReadShared code snippet:
action(Initiate_ReadShared_Hit) {
tbe.actions.push(Event:TagArrayRead);
tbe.actions.push(Event:ReadHitPipe);
tbe.actions.push(Event:DataArrayRead);
tbe.actions.push(Event:SendCompData);
tbe.actions.push(Event:WaitCompAck);
tbe.actions.pushNB(Event:TagArrayWrite);
}
TagArrayRead, ReadHitPipe, DataArrayRead, and TagArrayWrite don’t have any functional significance. They are there to introduce latencies that would exist in a real cache controller pipeline, in this case: tag read latency, hit pipeline latency, data array read latency, and tag update latency. The latency introduced by these action is defined by configuration parameters.
In addition to explicitly added latencies. SLICC has the concept of resource stalls to model resource contention. Given a set of actions executed during a transition, the SLICC compiler automatically generates code which checks if all resources needed by those actions are available. If any resource is unavailable, a resource stall is generated and the transition is not executed. A message that causes a resource stall remains in the input queue and the protocol attempts to trigger the transition again the next cycle.
Resources are detected by the SLICC compiler in different ways:
- Implicitly. This is the case for output ports. If an action enqueues new messages, the availability of the output port is automatically checked.
- Adding the
check_allocatestatement to an action. - Annotating the transition with a resource type.
We use (2) to check availability of TBEs. See the snippet below:
action(AllocateTBE_Snoop) {
// No retry for snoop requests; just create resource stall
check_allocate(storSnpTBEs);
...
}
This signals the SLICC compiler to check if the storSnpTBEs structure has a TBE slot available before executing any transition that includes the AllocateTBE_Snoop action.
The snippet below exemplifies (3):
transition({BUSY_INTR,BUSY_BLKD}, DataArrayWrite) {DataArrayWrite} {
...
}
The DataArrayWrite annotation signals the SLICC compiler to check for availability of the DataArrayWrite resource type. Resource request types used in these annotations must be explicitly defined by the protocol, as well as how to check them. In our protocol we defined the following types to check for the availability of banks in the cache tag and data arrays:
enumeration(RequestType) {
TagArrayRead;
TagArrayWrite;
DataArrayRead;
DataArrayWrite;
}
void recordRequestType(RequestType request_type, Addr addr) {
if (request_type == RequestType:DataArrayRead) {
cache.recordRequestType(CacheRequestType:DataArrayRead, addr);
}
...
}
bool checkResourceAvailable(RequestType request_type, Addr addr) {
if (request_type == RequestType:DataArrayRead) {
return cache.checkResourceAvailable(CacheResourceType:DataArray, addr);
}
...
}
The implementation of checkResourceAvailable and recordRequestType are required by SLICC compiler when we use annotations on transactions.
Cache block allocation and replacement modeling
Consider the following transaction initialization code for a ReadShared miss:
action(Initiate_ReadShared_Miss) {
tbe.actions.push(Event:ReadMissPipe);
tbe.actions.push(Event:TagArrayRead);
tbe.actions.push(Event:SendReadShared);
tbe.actions.push(Event:SendCompData);
tbe.actions.push(Event:WaitCompAck);
tbe.actions.push(Event:CheckCacheFill);
tbe.actions.push(Event:TagArrayWrite);
}
All transactions that modify a cache line or received cache line data as a result of a snoop or a request sent downstream, use the CheckCacheFill action trigger event. This event triggers a transition that perform the following actions:
- Checks if we need to store the current cache line data in the local cache.
- Checks if we already have a cache block allocated for that line. If not, attempts to allocate a block. If block not available, a victim block is selected for replacement.
- Models the latency of a cache fill.
When a replacement is performed, a new transaction is initialized to keep track of any WriteBack or Evict request sent downstream and/or snoops for backinvalidation (if the cache controller is configured the enforce inclusivity). Depending on the configuration parameters, the TBE for the replacement uses resources from a dedicated TBETable or reuses the same resources of the TBE that triggered the replacement. In both cases, the transaction that triggered the replacement completes without waiting for the replacement process.
Notice CheckCacheFill does not actually writes data to the cache block. If only ensures a cache block is allocated if needed, triggers replacements, and models the cache fill latencies. As described previously, TBE data is copied to the cache if needed during the transaction finalization.
Supported CHI transactions
All transactions are implemented as described in the AMBA5 CHI Issue D specification. The next sections provide a more detailed explanation of the implementation-specific choices not fixed by the public document.
Supported requests
The following incoming requests are supported:
ReadSharedReadNotSharedDirtyReadUniqueCleanUniqueReadOnceWriteUniquePtlandWriteUniqueFull
When receiving any request the clusivity configuration parameters are evaluated during the transaction initialization and the doCacheFill and dataToBeInvalid flags are set in the transaction buffer entry allocated for the request. doCacheFill indicates we should keep any valid copy of the line in the local cache;dataToBeInvalid indicates we must invalidate the local copy when completing the transaction.
When receiving ReadShared or ReadUnique, if the data is present at the local cache in the required state (e.g. UC or UD for ReadUnique), a CompData response is send to the requester. The response type depends on the value of dataToBeInvalid.
- If
dataToBeInvalid==true- The unique and/or dirty state is always propagated
- For a
ReadNotSharedDirty,CompData_SCis always sent if local state isSDand the line is written-back usingWriteCleanFull
- Else:
- In response to a
ReadUnique: propagate dirty state, i.e.,CompData_UDorCompData_UC. - In response to a
ReadSharedorReadNotSharedDirty: sendCompData_SC. Iffwd_unique_on_readsharedconfiguration parameter is set, theReadSharedis handled as aReadUniqueif the line doesn’t have other sharers.
- In response to a
When receiving a ReadOnce, CompData_I is always sent if the data is present at the local cache. For WriteUniquePtl handling see below.
If there is a cache miss, multiple actions may be performed depending on whether or not doCacheFill and dataToBeInvalid==false; and DCT or DMT is enabled:
ReadShared/ReadNotSharedDirty:- If dir state is
RSDorRU:- If DCT disabled: send
SnpSharedto owner; cache the line locally (ifdoCacheFill) and send response to requester. - If DCT enabled: send
SnpSharedFwdto owner; ifdoCacheFill==true, theretToSrcfield is set so the line can be cached locally.
- If DCT disabled: send
- If dir state is
RSC:- If DCT disabled: send
SnpOnceto one of the sharers; cache the line locally (ifdoCacheFill) and send response to requester. - If DCT enabled: send
SnpSharedFwdto one of the sharers; ifdoCacheFill==true, theretToSrcfield is set so the line can be cached locally.
- If DCT disabled: send
- Otherwise: issue a
ReadShared/ReadNotSharedDirtyorReadNoSnp(if HNF). In the HNF configuration,ReadNoSnpis issued with DMT if DMT is enabled. - For
ReadNotSharedDirty,SnpNotSharedDirtyandSnpNotSharedDirtyFwdis sent instead.
- If dir state is
ReadUnique:- If dir state is
RU,RUSD,RUSC:- If DCT disabled or clusivity is inclusive: send
SnpUniqueto owner; cache the line locally (ifdoCacheFill) and sent response to requester. - If DCT enabled and clusivity is exclusive: send
SnpUniqueFwdto owner.
- If DCT disabled or clusivity is inclusive: send
- If dir state is
RSC/RSD:- Send
SnpUniquewithretToSrc=trueto invalidate sharers and obtain dirty line (in case ofRSD) - If not HNF: send
CleanUniquedownstream to obtain unique permissions.
- Send
- Otherwise: issue a
ReadUniqueorReadNoSnp(if HNF). In the HNF configuration,ReadNoSnpis issued with DMT if DMT is enabled. - For
RUSCamdRSC, if multiple sharers, only one sharer is selected as target of the above snoops. The other sharers are invalidated usingSnpUniquewithretToSrc=false.
- If dir state is
ReadOnce:- If dir entry exists:
- If DCT disabled: send
SnpOnceto one of the sharers; send received data response to requester. - If DCT enabled: send
SnpOnceFwdto one of the sharers.
- If DCT disabled: send
- Otherwise: issue a
ReadOnceorReadNoSnp(if HNF). In the HNF configuration,ReadNoSnpis issued with DMT if DMT is enabled.
- If dir entry exists:
CleanUnique:- Send
SnpCleanInvalidto all sharers/owner except original requestor. - If not HNF: send
CleanUniquedownstream to obtain unique permissions. - If has dirty line, requestor has clean line, and
doCacheFill==false: writeback the line withWriteCleanFull.
- Send
WriteUniquePtl/WriteUniqueFull:- If data present in local cache on UC or UD states:
- Issue
SnpCleanInvalidif there are any sharers. - Perform the write in the local cache.
- Issue
- If no UC/UD data locally:
- If HNF:
- Issue
SnpCleanInvalidif there are any sharers. - Merge any received snoop response data with the WriteUnique data.
- If has a full line and
doCacheFillset, cache the line locally, otherwise writeback to memory (WriteNoSnporWriteNoSnpPtl).
- Issue
- If no HNF:
- Forwards the
WriteUniquePtland any received data to the downstream cache. - Incoming snoops will cause any locally cached data to become invalid while handling the request.
- Forwards the
- If HNF:
- If data present in local cache on UC or UD states:
Supported snoops
The cache controller issues and accepts the following snoops:
SnpSharedandSnpSharedFwdSnpNotSharedDirtyandSnpNotSharedDirtyFwdSnpUniqueandSnpUniqueFwdSnpCleanInvalidSnpOnceandSnpOnceFwd
The snoop response is generated according to the current state of the line as defined in the specification. Data is returned with the snoop response depending on the data state and the value of retToSrc set by the snooper. If retToSrc is set, the snoop response always includes data.
SnpShared/SnpNotSharedDirty:- Snoopee always returns data is the line is dirty, unique or
retToSrc. retToSrcis set if the snooper needs to cache the line.- Final snoopee state always shared clean.
- Snoopee always returns data is the line is dirty, unique or
SnpUnique:- Snoopee always returns data is the line is dirty, unique or
retToSrc. retToSrcis set if the snooper needs to cache the line.- Final snoopee state always invalid.
- Snoopee always returns data is the line is dirty, unique or
SnpCleanInvalid:- Same as SnpUnique, except data is not returned if line is unique and clean.
SnpSharedFwd:retToSrcis set if the snooper needs to cache the line.- Line forwarded as dirty if dirty
- Final snoopee state always shared clean
SnpNotSharedDirtyFwd:retToSrcis set if the snooper needs to cache the line.- Always returns data if line was dirty at the snoopee; line always forwarded as clean.
- Final snoopee state always shared clean.
SnpUniqueFwd:- Same as SnpUnique, except data is never returned to the snooper (as defined by the spec)
SnpOnce:- Always generated with
retToSrc=trueand snoopee always returns data. - Accepted in any state (except invalid). Final snoopee state does not change.
- Always generated with
SnpOnceFwd:- Same as SnpOnce, except data is never returned to the snooper.
If the snoopee has sharers in any state, the same request is sent upstream to all sharers. For SnpSharedFwd/SnpNotSharedDirtyFwd and SnpUniqueFwd, a SnpShared/SnpNotSharedFwd or SnpUnique is sent, respectively. For a received SnpOnce, a SnpOnce is sent upstream only if the line is not present locally. In this particular implementation, there is always a directory entry for upstream caches that have the line. Snoops are never sent to caches that do not have the line.
Writeback and evictions
A writeback is triggered internally by the controller when a cache line needs to be evicted due to capacity reasons (cache maintenance operations are currently not supported). See Section Cache block allocation and replacement modeling for more information on replacements. These internal events are generated depending on the configurations parameters of the controller:
GlobalEviction: evict a line from the current and all upstream caches. This applies ifdealloc_backinv_uniqueordealloc_backinv_sharedparameters are set.LocalEviction: evict a line without backinvaliding upstream caches.
First we deallocate the local cache block (so the request that cause the eviction can allocate a new block and finish). For GlobalEviction, a SnpCleanInvalid is sent to all upstream caches. Once all snoops responses are received (possibly with dirty data), a LocalEviction is performed. The LocalEviction is done by issuing the appropriate request as follows:
WriteBackFull, if the the line is dirtyWriteEvictFull, if the line is unique and cleanWriteCleanFull, if the the line is dirty, but there are clean sharersEvict, if the line is shared and clean
For a HNF configuration the behavior changes slightly: WriteNoSnp to the SNF is used instead of WriteBackFull and no requests are issued if the line is clean.
The WriteBack* and Evict requests are handled at the downstream cache as follows:
WriteBackFull/WriteEvictFull/WriteCleanFull:- If
alloc_on_writeback, a cache block may need to be allocated. If there are no free blocks, a LocalEviction is triggered for a cache line in the target cache set. The victim line is selected based on the replacement policy implemented by object pointed by thecacheparameter (which can be configured separately). - Send a
CompDBIDRespto the requester. - Once data is received, update local cache and remove requestor from directory (if
WriteBackFull/WriteEvictFull).
- If
Evict:- Remove requestor from directory and reply with
Comp\_I.
- Remove requestor from directory and reply with
Hazards
A request for a line that currently has an outstanding transaction is always stalled until the transaction completes. Snoops received while there is an outstanding request are handled following the requirements in the specification:
- For an outstanding
CleanUnique:- Snoop response is sent immediately and the current line state is changed accordingly.
- Notice we don’t model the UCE and UDP states from the CHI spec. If the line is invalidated while the requester waits for a
CleanUniqueresponse, it immediately follows up with aReadUnique.
- For outstanding
WriteBackFull/WriteEvictFull/WriteCleanFullthat have not yet been acked with aCompDBIDResp; or Evict beforeComp_Iis received:- Snoop response is sent immediately and the current line state is changed accordingly.
- The state of the line that will be written back will the state after the snoop.
- If a snoop is received while the current transaction is waiting for snoop responses from upstream caches, the incoming snoop is stalled until all pending responses from upstream are received and any follow-up request is sent. This can happen in these scenarios:
- During a global replacement
- An accepted
ReadUniquethat required snooping upstream caches
Multiple snoops may be received while there is an outstanding transaction. In this particular implementation, a SnpShared or SnpSharedFwd may be followed by a SnpUnique or SnpCleanInvalid. However, it’s not possible to have concurrent snoops coming from the downstream cache.
Both incoming requests and snoops require the allocation of a TBE. To prevent deadlocks when transaction buffers are full, a separate buffer is used to allocate snoop TBEs. Snoops do not allow retry, so if the snoop TBE table is full messages in the snpIn port are stalled, potentially causing severe congestion in the snoop channel in the interconnect.
Other implementations notes
- If an HNF uses DMT, it will send
ReadNoSnpSepinstead ofReadNoSnpif theenable_DMT_early_deallocconfiguration parameter is set. This allow the HNF to deallocate the TBE earlier. - Order bit field is not implemented, thus
ReadReceiptresponses are never used except forReadNoSnpSep. Request ordering, when required, is enforced by Ruby by serializing requests at the requester. At the cache controller, requests to the same line are handled in the order of arrival. Requests to different lines can be handled in any order, however they are typically handled in order of arrival given that there are resources available. - Exclusive accesses and atomic requests are not implemented. Ruby has its own global monitor in the Sequencer to manage exclusive load and stores. Atomic operations also handled by Ruby and they only require a
ReadUniqueat the protocol level. CompAckresponse is always sent when stated as optional in the spec. Requesters always wait forCompAck(if required or optional) before finalizing the transaction and deallocating resources.- Separate
CompandDBIDrespused only forWriteUniquerequests.DBIDrespis sent after receiving all snoop responses;Compis sent afterDBIDrespand accounting for the front-end write latency (write_fe_latency). - Memory attribute fields are not implemented.
DoNotGoToSDfield is not implemented.CBusyis not implemented.WriteDataCancelresponses are never used.- Error handling is not implemented.
- Cache stashing is not implemented.
- Atomic transactions are not implemented.
- DMV transactions are not implemented.
- Any request not listed in the protocol table below is not supported in this implementation.