Arm's Transactional Memory Extension support in gem5
This post was originally posted on the Arm Research Blog: here
April 16 2021: The code example in this article has been updated to reflect the Armv9-A architecture release and to be functional with respect to the gem5/ruby model.
A shift to concurrency
In 2005, Herb Sutter published his seminal article “The Free Lunch is Over” (Sutter, 2005). He outlined that the sequential performance of microprocessors would soon plateau, and the industry would respond by offering more performant processors by way of increased core counts. The consequence of this paradigm shift has been a move away from a purely sequential programming model for writing software to that of a concurrent one with multiple threads of execution. When applications inherently exhibit parallelism, dividing work between multiple threads can yield performance gains when the threads execute on different cores.
Multithreading concurrency has two principal drawbacks—(1) the overheads of synchronization, for example, the serializing nature of locks, and (2) its difficulty to program, debug and verify. There is often an inverse correlation between these two properties when characterizing different synchronization strategies, for example, coarse-grained locking, fine-grained locking and lock-free algorithms.
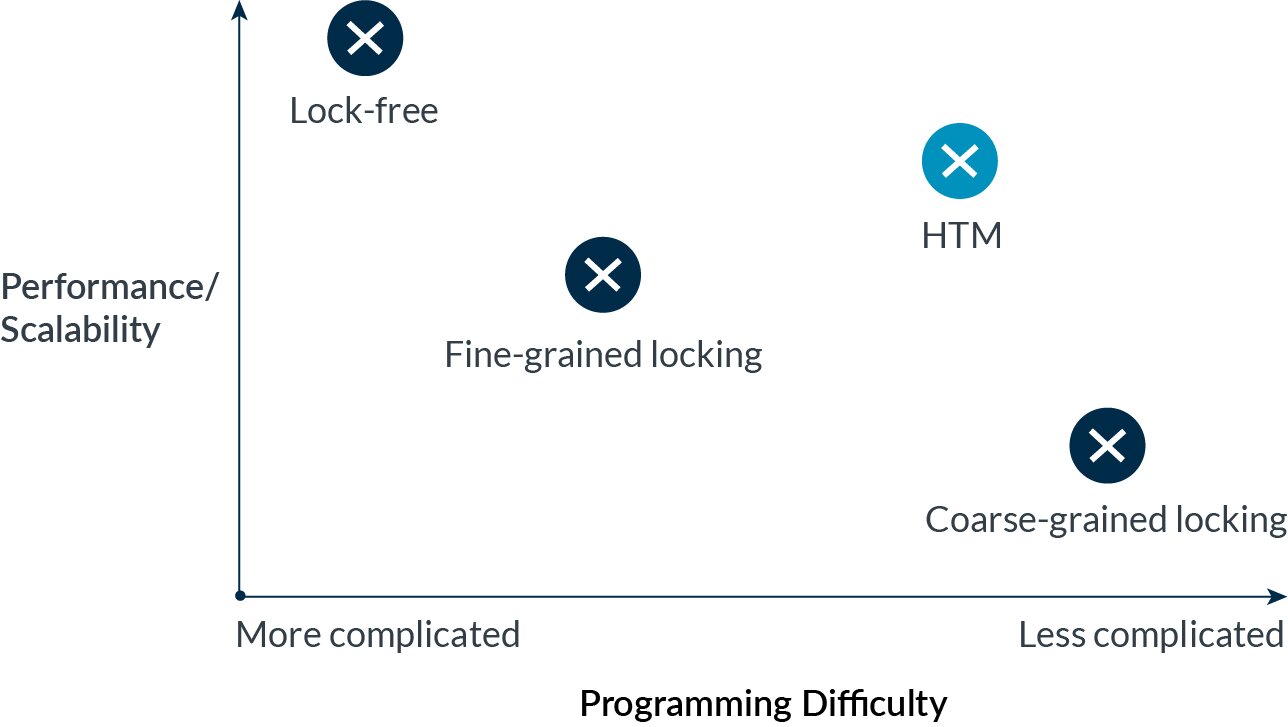
Figure 1: Achieving more performant/scalable concurrency often comes at the cost of increased difficulty.
Hardware Transactional Memory (HTM) allows two or more threads to safely execute critical sections—a.k.a. transactions—in parallel without using serializing primitives such as mutexes. Transactions are executed speculatively with the properties of atomicity, consistency and isolation (Harris, et al., 2007), and the microarchitecture is in charge of detecting and recovering from race conditions. For example, if one thread writes to a memory location that another thread has read. This can provide increased parallelism with a simpler programming model.
Arm’s TME
The Transactional Memory Extension (TME) is an optional feature of Armv9 (previously a part of Arm’s A-profile Future Architecture Technologies program). TME is a best effort HTM architecture which does not guarantee completion of transactions. The programmer must provide a fallback path to guarantee progress, such as a mutex-guarded critical section. It provides strong isolation, meaning transactions are isolated from both other transactions, and concurrent non-transactional memory accesses. It uses flattened nesting of transactions, in which nested transactions are subsumed by the outer transaction. The effects of a nested transaction do not become visible to other observers until the outer transaction commits. When a nested transaction aborts, it causes the outer transaction (and all its nested transactions within) to abort.
TME comprises four instructions:
-
TSTART <Xd> - This instruction starts a new transaction. If the transaction started successfully, the destination register is set to zero and the processor enters transactional state. If the transaction failed or was canceled, then all state modifications that were performed transactionally are discarded. The destination register is then written with a nonzero value that encodes the cause of the failure.
-
TCOMMIT - This instruction commits the current transaction. If the current transaction is an outer transaction, then transactional state is exited, and all state modifications performed transactionally are committed to the architectural state.
-
TCANCEL #<imm> - This instruction exits transactional state and discards all state modifications that were performed transactionally. Execution continues at the instruction that follows the
TSTARTinstruction of the outer transaction. The destination register of theTSTARTinstruction of the outer transaction is written with the immediate operand ofTCANCEL. -
TTEST <Xd> - This instruction writes the depth of the transaction to the destination register, or the value 0 otherwise.
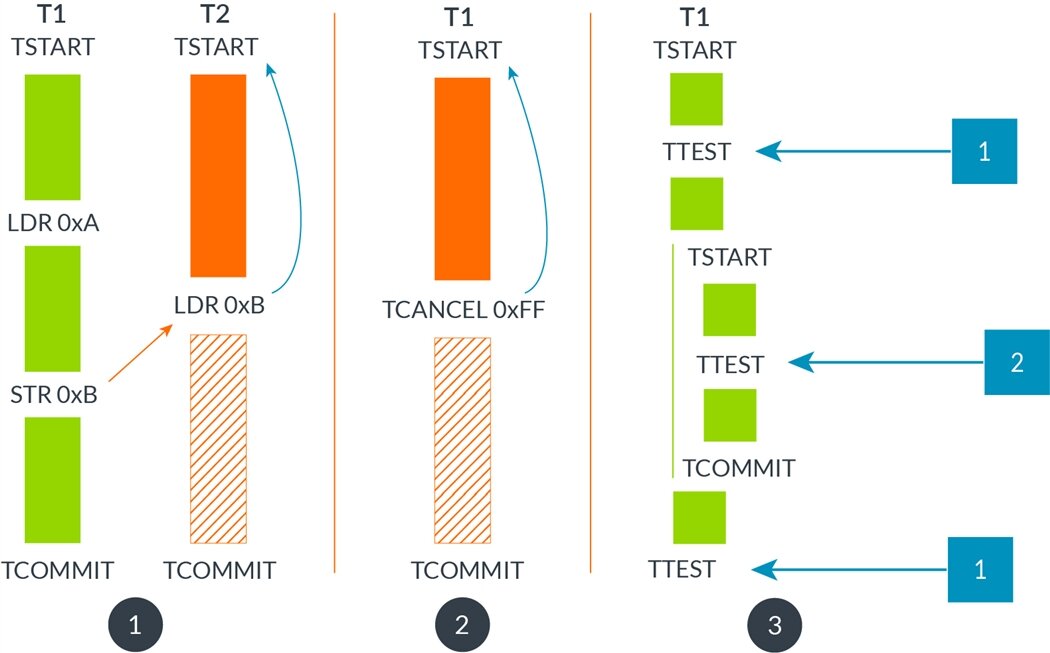
Figure 2: Illustrates the semantics of the four TME instructions. (1) shows two threads creating and committing transactions. Thread T1 conflicts with thread T2, therefore T2 aborts its transaction and rolls back to the TSTART instruction. T2’s TCOMMIT is never reached. (2) thread T1 creates a transaction but manually aborts it using TCANCEL. It aborts and rolls back to TSTART. T1’s TCOMMIT is never reached. (3) thread T1 creates and commits a nested transaction in which the transactional depth is tested. When TTEST is executed in the outer transaction it returns 1, whereas if it is executed in the inner transaction it returns 2.
Modelling TME in gem5
gem5 is an open-source system and processor simulator widely used in academia and industry for computer architecture research. gem5 offers two alternative memory systems—classic and Ruby. The Classic Memory System is inherited from gem5’s predecessor, M5, and implements a MOESI coherence protocol (Sorin, Hill, & Wood, 2011). In contrast, the Ruby Memory System offers a flexible way of defining and emulating custom cache coherence protocols, including a range of interconnects and topologies. Protocols are specified through states, transitions, events, and actions using the domain-specific language, SLICC (specification language including cache coherence). gem5 includes a variety of Ruby cache coherence protocols available for use by default, however, none of these protocols currently support HTM.
HTM can be implemented in many ways with different trade-offs. To prototype Arm’s TME, we have chosen one particular way of implementing the ISA extension in the microarchitecture. In short, it uses lazy version management and eager conflict detection with a cache line granularity (Bobba, et al., 2007). Other implementations are possible and the choices for the gem5 design do not necessarily reflect any silicon implementation – existing or future.
TME requires that implementations must:
- Checkpoint and restore the architectural register state.
- Track transactionally read and written state.
- Buffer speculative memory updates.
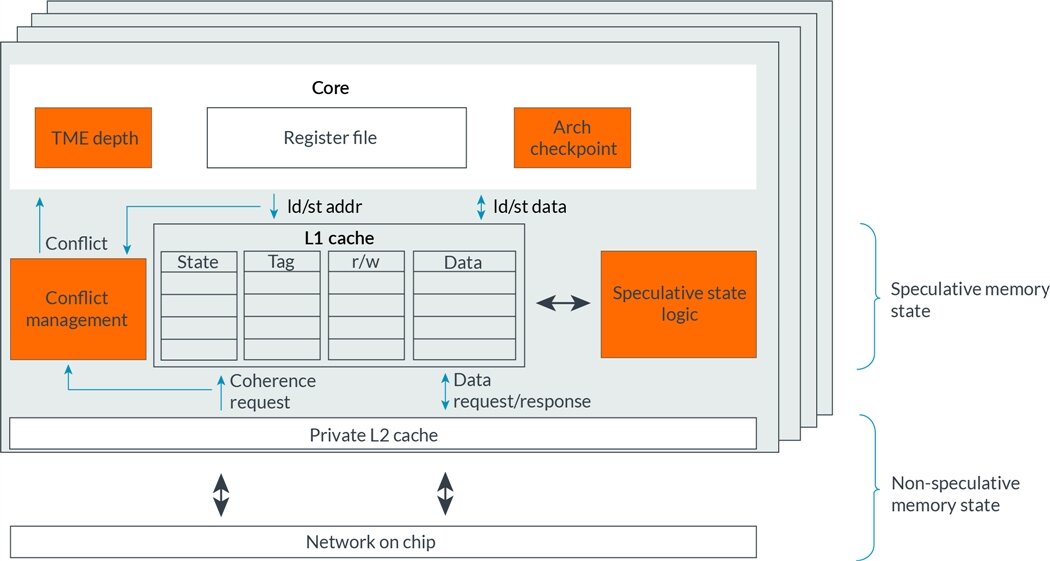
Figure 3: The boxes highlighted in orange are components in the microarchitecture that have been added or modified to accommodate TME support.
There are several techniques that can be used for register checkpointing, including shadow register files and freezing physical registers. In gem5, we opt for a functionally correct checkpointing mechanism with no overhead, that is, a zero-cycle instantaneous backup of the entire register file. This allows us to share a common checkpointing mechanism between core models.
To separate the HTM support from TME-specific functionality, a generic interface for checkpoint creation and restoration is added to src/arch/ directory. ISAs can implement this interface according to their particular needs, allowing much of the HTM functionality to be shared and reused. The TME implementation must also be able to roll back the architectural state and discard speculative updates on transactional failure or cancellation. This is achieved by repurposing gem5’s exception mechanism.
To track a transaction’s read/write sets and buffer speculative memory updates, we leverage the cache coherence protocol. gem5 includes the Ruby protocol MESI_Three_Level. MESI refers to the states that a cache line can be in: Modified, exclusive, shared or invalid (Sorin, Hill, & Wood, 2011). The protocol utilizes private L1 data and instruction caches that are fed by a larger unified inclusive private L2 cache. The L2 caches are backed by a larger inclusive shared L3 cache and coherence directory.
The MESI_Three_Level protocol has been augmented to support TME. The L1 data cache is used to buffer speculative state isolated from the rest of the system. Because the L2 cache is inclusive, it contains the same lines used in a transaction’s read/write sets, but holds their pre-transactional values. The consequence of this configuration is that a transaction’s working set must reside solely in the L1 data cache. If a transactionally read or written line spills, that is, is evicted from the L1 data cache to the L2 cache, the transaction must abort, and any speculatively written data must be discarded.
To track transactionally read and written states, two additional ‘bits’ are added to the tags of each L1 data cache line - 1 bit if it is in a transaction’s read set and the other bit if it is in the write set. These bits are then used when transitioning from one cache line state to another. To commit a transaction, both bits are cleared. To abort a transaction, the line is transitioned to invalid if it is both modified and in the transaction’s write set; similar to committing, both bits are also cleared. We assume these bits can be cleared atomically so that to external observers, either all the transactional state commits (becomes non-speculative), or is discarded and rolls back. This satisfies the transactional memory property of atomicity.
Example program
To test the new functionality in gem5, we outline a simple program written in C that uses TME transactions to update a histogram in parallel. This program uses manual lock elision—a lock is used to protect a shared data structure but is bypassed, that is, elided, whenever possible in favor of transactions. This satisfies the requirements of a fallback path if a transaction cannot make progress.
We first define a very simple spinlock that works both with AArch64’s weak memory model and TME. Arm’s recommended locking acquisition sequences using Load-Exclusive/Store-Exclusive typically rely on a load-acquire exclusive instruction (e.g. LDAXR) for correct memory ordering. When this form of lock acquisition is used in conjunction with TME lock elision, mutual exclusion cannot be guaranteed.. To circumvent this issue, two solutions are possible:
- To construct a locking acquisition sequence using Armv8.1 Large System Extensions (LSE) atomics. This is the idiomatic and performant Armv8-A and Armv9-A locking sequence which can be found in the Linux kernel.
- To add a full memory barrier (DMB SY) before the first memory operation of the critical section.
Since LSE atomics aren’t currently implemented in gem5/ruby we use the second option.
#include <stdatomic.h>
typedef atomic_int lock_t;
inline void lock_init(lock_t *lock) {
atomic_init(lock, 0);
}
inline void lock_acquire(lock_t *lock) {
// The following atomic exchange can use relaxed memory
// ordering since it is followed by a full barrier.
while (atomic_exchange_explicit(lock, 1, memory_order_relaxed))
; // spin until acquired
// This will generate a full memory barrier, e.g. DMB SY
atomic_thread_fence(memory_order_seq_cst);
}
inline int lock_is_acquired(lock_t *lock) {
return atomic_load_explicit(lock, memory_order_acquire);
}
inline void lock_release(lock_t *lock) {
atomic_store_explicit(lock, 0, memory_order_release);
}
Next, we write a function to elide the lock using a TME transaction. lock_acquire_elided returns 1 if the lock was successfully elided otherwise 0. The function starts a new transaction and checks that the lock is still free, therefore adding it to the transaction’s read set. If the lock is not free, the transaction is aborted explicitly via TCANCEL. The particular 15-bit integer passed as a parameter is unimportant in our example, however, setting the MSB ensures the transaction can be retried.
#include <arm_acle.h>
#define TME_MAX_RETRIES 3
#define TME_LOCK_IS_ACQUIRED 65535
int lock_acquire_elided(lock_t *lock) {
int num_retries = 0;
uint64_t status;
do {
status = __tstart();
if (status == 0) {
// check if lock is acquired and add it to our read-set
if (lock_is_acquired(lock)) {
__tcancel(TME_LOCK_IS_ACQUIRED);
__builtin_unreachable();
}
return 1;
}
++num_retries;
} while ((status & _TMFAILURE_RTRY) && (num_retries < TME_MAX_RETRIES));
// the transaction failed too many times
return 0;
}
void lock_release_elided() {
__tcommit();
}
These spinlock and transaction routines are then leveraged to create the function work that updates a global shared array structure on the heap. This function can be called from multiple threads in parallel.
#include <stdio.h>
#include <stdlib.h>
#include "lock.h"
#define ARRAYSIZE 512
#define ITERATIONS 10000
volatile long int histogram[ARRAYSIZE];
lock_t global_lock;
void* work(void* void_ptr) {
// Use thread id for RNG seed,
// this will prevent threads generating the same array indices.
long int idx = (long int)void_ptr;
unsigned int seedp = (unsigned int)idx;
int i, rc;
printf("Hello from thread %ld\n", idx);
for (i=0; i<ITERATIONS; i++)
{
int num1 = rand_r(&seedp)%ARRAYSIZE;
rc = lock_acquire_elided(&global_lock);
if (rc == 0) // eliding the lock failed
lock_acquire(&global_lock);
// start critical section
long int temp = histogram[num1];
temp += 1;
histogram[num1] = temp;
// end critical section
if (rc == 1)
lock_release_elided();
else
lock_release(&global_lock);
}
printf("Goodbye from thread %ld\n", idx);
}
Finally, we put this all together using a main function that spawns and joins worker threads.
#include <assert.h>
#include <pthread.h>
#include <unistd.h>
int main() {
long int i, total, numberOfProcessors;
pthread_t *threads;
int rc;
numberOfProcessors = sysconf(_SC_NPROCESSORS_ONLN);
printf("TME parallel histogram with %ld procs\n", numberOfProcessors);
lock_init(&global_lock);
// initialise the array
for (i=0; i<ARRAYSIZE; i++)
histogram[i] = 0;
// spawn work
threads = (pthread_t*) malloc(sizeof(pthread_t)*numberOfProcessors);
for (i=0; i<numberOfProcessors-1; i++) {
rc = pthread_create(&threads[i], NULL, work, (void*)i);
assert(rc==0);
}
work((void*)(numberOfProcessors-1));
// wait for worker threads
for (i=0; i<numberOfProcessors-1; i++) {
rc = pthread_join(threads[i], NULL);
assert(rc==0);
}
// verify array contents
total = 0;
for (i=0; i<ARRAYSIZE; i++)
total += histogram[i];
// free resources
free(threads);
printf("Total is %lu\nExpected total is %lu\n",
total, ITERATIONS*numberOfProcessors);
return 0;
}
Compiling and running
TME is supported in GCC as of version 10—this includes ACLE intrinsics. To compile source files with TME instructions, an AArch64 compiler must be used with the feature enabled via the march flag, for example, -march=armv8-a+tme.
aarch64-linux-gnu-gcc -std=c11 -O2 -static -march=armv8-a+tme+nolse -pthread -o histogram.exe ./histogram.c
As of this writing, gem5 implements Arm’s Large System Extension (LSE) in the Classic memory system but not Ruby. In order to easily use system emulation mode, this feature should be disabled in the source tree. To do this in gem5 v20.1, modify ./src/arch/arm/isa.cc:l106 and change haveLSE from true to false.
gem5 must then be compiled with the new Ruby MESI_Three_Level_HTM protocol.
scons CC=gcc CXX=g++ build/ARM_MESI_Three_Level_HTM/gem5.opt TARGET_ISA=arm PROTOCOL=MESI_Three_Level_HTM SLICC_HTML=True CPU_MODELS=AtomicSimpleCPU,TimingSimpleCPU,O3CPU -j 4
To run the histogram executable in system emulation mode
./gem5/build/ARM_MESI_Three_Level_HTM/gem5.opt ./gem5/configs/example/se.py --ruby --num-cpus=2 --cpu-type=TimingSimpleCPU --cmd=./blogexample/histogram.exe
The output should look something like:
TME parallel histogram with 2 procs
Hello from thread 1
Hello from thread 0
Goodbye from thread 1
Goodbye from thread 0
Total is 20000
Expected total is 20000
Exiting @ tick 718668000 because exiting with last active thread context
To verify whether any critical sections executed transactionally, we check m5out/stats.txt where several HTM-related statistics live.
system.ruby.l0_cntrl0.sequencer.htm_transaction_abort_cause::explicit 35 22.01% 22.01% # cause of htm transaction abort
system.ruby.l0_cntrl0.sequencer.htm_transaction_abort_cause::transaction_size 38 23.90% 45.91% # cause of htm transaction abort
system.ruby.l0_cntrl0.sequencer.htm_transaction_abort_cause::memory_conflict 86 54.09% 100.00% # cause of htm transaction abort
system.ruby.l0_cntrl0.sequencer.htm_transaction_abort_cause::total 159 # cause of htm transaction abort
system.ruby.l0_cntrl0.sequencer.htm_transaction_cycles::samples 9927 # number of cycles spent in an outer transaction
system.ruby.l0_cntrl0.sequencer.htm_transaction_cycles::mean 63.466103 # number of cycles spent in an outer transaction
system.ruby.l0_cntrl0.sequencer.htm_transaction_cycles::gmean 56.438036 # number of cycles spent in an outer transaction
system.ruby.l0_cntrl0.sequencer.htm_transaction_cycles::stdev 29.029108 # number of cycles spent in an outer transaction
system.ruby.l0_cntrl0.sequencer.htm_transaction_cycles::32-47 4854 48.90% 48.90% # number of cycles spent in an outer transaction
system.ruby.l0_cntrl0.sequencer.htm_transaction_cycles::48-63 2 0.02% 48.92% # number of cycles spent in an outer transaction
system.ruby.l0_cntrl0.sequencer.htm_transaction_cycles::64-79 195 1.96% 50.88% # number of cycles spent in an outer transaction
system.ruby.l0_cntrl0.sequencer.htm_transaction_cycles::80-95 4627 46.61% 97.49% # number of cycles spent in an outer transaction
system.ruby.l0_cntrl0.sequencer.htm_transaction_cycles::96-111 188 1.89% 99.39% # number of cycles spent in an outer transaction
system.ruby.l0_cntrl0.sequencer.htm_transaction_cycles::112-127 60 0.60% 99.99% # number of cycles spent in an outer transaction
system.ruby.l0_cntrl0.sequencer.htm_transaction_cycles::128-143 1 0.01% 100.00% # number of cycles spent in an outer transaction
system.ruby.l0_cntrl0.sequencer.htm_transaction_cycles::total 9927 # number of cycles spent in an outer transaction
system.ruby.l0_cntrl0.sequencer.htm_transaction_instructions::samples 9927 # number of instructions spent in an outer transaction
system.ruby.l0_cntrl0.sequencer.htm_transaction_instructions::mean 12 # number of instructions spent in an outer transaction
system.ruby.l0_cntrl0.sequencer.htm_transaction_instructions::gmean 12.000000 # number of instructions spent in an outer transaction
system.ruby.l0_cntrl0.sequencer.htm_transaction_instructions::12-13 9927 100.00% 100.00% # number of instructions spent in an outer transaction
system.ruby.l0_cntrl0.sequencer.htm_transaction_instructions::total 9927 # number of instructions spent in an outer transaction
These are per-core statistics that provide information about the lengths of the transactions (in number of cycles or number of instructions), as well as the reason for aborting a transaction. explicit is incremented when TCANCEL is used—in our example code, this happens when the global lock is observed to be taken after the transaction has already started. memory_conflict occurs when another processing element attempts to modify a cache line in the transaction’s read or write sets. transaction_size indicates that the transaction spilled out of the L1 data cache; since this is difficult to track accurately, the statistics instead capture transactional cache lines that are evicted from the L1 data cache due to a load/store originating in the same core. Due to factors such as the cache set replacement policy, this statistic often exhibits false positives.
system.ruby.l0_cntrl0.Dcache.htm_transaction_aborted_read_set::samples 159 # read set size of a aborted transaction
system.ruby.l0_cntrl0.Dcache.htm_transaction_aborted_read_set::mean 0.729560 # read set size of a aborted transaction
system.ruby.l0_cntrl0.Dcache.htm_transaction_aborted_read_set::stdev 0.591988 # read set size of a aborted transaction
system.ruby.l0_cntrl0.Dcache.htm_transaction_aborted_read_set::0 55 34.59% 34.59% # read set size of a aborted transaction
system.ruby.l0_cntrl0.Dcache.htm_transaction_aborted_read_set::1 92 57.86% 92.45% # read set size of a aborted transaction
system.ruby.l0_cntrl0.Dcache.htm_transaction_aborted_read_set::2 12 7.55% 100.00% # read set size of a aborted transaction
system.ruby.l0_cntrl0.Dcache.htm_transaction_aborted_read_set::total 159 # read set size of a aborted transaction
system.ruby.l0_cntrl0.Dcache.htm_transaction_aborted_write_set::samples 159 # write set size of a aborted transaction
system.ruby.l0_cntrl0.Dcache.htm_transaction_aborted_write_set::mean 0.169811 # write set size of a aborted transaction
system.ruby.l0_cntrl0.Dcache.htm_transaction_aborted_write_set::stdev 0.376653 # write set size of a aborted transaction
system.ruby.l0_cntrl0.Dcache.htm_transaction_aborted_write_set::0 132 83.02% 83.02% # write set size of a aborted transaction
system.ruby.l0_cntrl0.Dcache.htm_transaction_aborted_write_set::1 27 16.98% 100.00% # write set size of a aborted transaction
system.ruby.l0_cntrl0.Dcache.htm_transaction_aborted_write_set::total 159 # write set size of a aborted transaction
system.ruby.l0_cntrl0.Dcache.htm_transaction_committed_read_set::samples 9927 # read set size of a committed transaction
system.ruby.l0_cntrl0.Dcache.htm_transaction_committed_read_set::mean 1.987710 # read set size of a committed transaction
system.ruby.l0_cntrl0.Dcache.htm_transaction_committed_read_set::gmean 1.983035 # read set size of a committed transaction
system.ruby.l0_cntrl0.Dcache.htm_transaction_committed_read_set::stdev 0.110181 # read set size of a committed transaction
system.ruby.l0_cntrl0.Dcache.htm_transaction_committed_read_set::1 122 1.23% 1.23% # read set size of a committed transaction
system.ruby.l0_cntrl0.Dcache.htm_transaction_committed_read_set::2 9805 98.77% 100.00% # read set size of a committed transaction
system.ruby.l0_cntrl0.Dcache.htm_transaction_committed_read_set::total 9927 # read set size of a committed transaction
system.ruby.l0_cntrl0.Dcache.htm_transaction_committed_write_set::samples 9927 # write set size of a committed transaction
system.ruby.l0_cntrl0.Dcache.htm_transaction_committed_write_set::mean 1 # write set size of a committed transaction
system.ruby.l0_cntrl0.Dcache.htm_transaction_committed_write_set::gmean 1 # write set size of a committed transaction
system.ruby.l0_cntrl0.Dcache.htm_transaction_committed_write_set::1 9927 100.00% 100.00% # write set size of a committed transaction
system.ruby.l0_cntrl0.Dcache.htm_transaction_committed_write_set::total 9927 # write set size of a committed transaction
These are sampled histograms containing the sizes of transactions in terms of number of cache lines used. It can be observed that the majority of successful transactions read from two unique cache lines and write to one. These are useful metrics when characterizing TME-enabled applications.
Available now
Arm is dedicated to working with the open-source software community, and views the innovation it enables as essential to the ongoing success of its ecosystem. Arm’s TME support in gem5 has been open-sourced and upstreamed; it is available from v20.1 onwards. This enables many useful use cases for our commercial and academic partners, some examples being:
- Testing and benchmarking TME-enabled binaries before general silicon availability
- Sensitivity analyses to determine how different microarchitectural parameters impact the efficacy of a TME implementation
- As a research platform to discover and demonstrate how this technology could evolve.
This work was in collaboration with Cray, and funded in part by the DOE ECP PathForward program. The code is based on a previous pull request by Pradip Vallathol, who developed HTM and TSX support in gem5 as part of his master’s thesis. The author would like to thank all of the internal and external code reviewers.
Works cited
Bobba, J., Moore, K. E., Volos, H., Yen, L., Hill, M. D., Swift, M. M., & Wood, D. A. (2007). Performance pathologies in hardware transactional memory. ACM SIGARCH Computer Architecture News, 35(2), 81-91.
Harris, T., Cristal, A., Unsal, O. S., Ayguade, E., Gagliardi, F., Smith, B., & Valero, M. (2007, August 20). Transactional Memory: An Overview. IEEE Micro, 27(3), pp. 8-29.
Sorin, D. J., Hill, M. D., & Wood, D. A. (2011). A Primer on Memory Consistency and Cache Coherence. Synthesis lectures on computer architecture, 6(3), 1-212.
Sutter, H. (2005). The free lunch is over: A fundamental turn toward concurrency in software. Dr. Dobb’s journal, 30(3), 202-210.