
Execution basic
gem5 bootcamp 2022 module on instruction execution
gem5 bootcamp (2022) had a session on learning how instructions work in gem5 and how to add new instructions in gem5. The slides presented in the session can be found here.
The youtube video of the recorded bootcamp module on gem5 instructions is available here.
StaticInsts
The StaticInst provides all static information and methods for a binary instruction.
It holds the following information/methods:
- Flags to tell what kind of instruction it is (integer, floating point, branch, memory barrier, etc.)
- The op class of the instruction
- The number of source and destination registers
- The number of integer and FP registers used
- Method to decode a binary instruction into a StaticInst
- Virtual function execute(), which defines how the specific architectural actions taken for an instruction (e.g. read r1, r2, add them and store in r3.)
- Virtual functions to handle starting and completing memory operations
- Virtual functions to execute the address calculation and memory access separately for models that split memory operations into two operations
- Method to disassemble the instruction, printing it out in a human readable format. (e.g. addq r1 r2 r3)
It does not have dynamic information, such as the PC of the instruction or the values of the source registers or the result. This allows a 1 to 1 mapping of StaticInst to unique binary machine instructions. We take advantage of this fact by caching the mapping of a binary instruction to a StaticInst in a hash_map, allowing us to decode a binary instruction only once, and directly using the StaticInst the rest of the time.
Each ISA instruction derives from StaticInst and implements its own constructor, the execute() function, and, if it is a memory instruction, the memory access functions. See ISA_description_system for details about how these ISA instructions are specified.
DynInsts
The DynInst is used to hold dynamic information about instructions. This is necessary for more detailed models or out-of-order models, both of which may need extra information beyond the StaticInsts in order to correctly execute instructions. Some of the dynamic information that it stores includes:
- The PC of the instruction
- The renamed register indices of the source and destination registers
- The predicted next-PC
- The instruction result
- The thread number of the instruction
- The CPU the instruction is executing on
- Whether or not the instruction is squashed
Additionally the DynInst provides the ExecContext interface. When ISA instructions are executed, the DynInst is passed in as the ExecContext, handling all accesses of the ISA to CPU state.
Detailed CPU models can derive from DynInst and create their own specific DynInst subclasses that implement any additional state or functions that might be needed. See src/cpu/o3/alpha/dyn_inst.hh for an example of this.
Microcode support
ExecContext
The ExecContext describes the interface that the ISA uses to access CPU state. Although there is a file src/cpu/exec_context.hh, it is purely for documentation purposes and classes do not derive from it. Instead, ExecContext is an implicit interface that is assumed by the ISA.
The ExecContext interface provides methods to:
- Read and write PC information
- Read and write integer, floating point, and control registers
- Read and write memory
- Record and return the address of a memory access, prefetching, and trigger a system call
- Trigger some full-system mode functionality
Example implementations of the ExecContext interface include:
- SimpleCPU
- DynInst
See the ISA description page for more details on how an instruction set is implemented.
ThreadContext
ThreadContext is the interface to all state of a thread for anything outside of the CPU. It provides methods to read or write state that might be needed by external objects, such as the PC, next PC, integer and FP registers, and IPRs. It also provides functions to get pointers to important thread-related classes, such as the ITB, DTB, System, kernel statistics, and memory ports. It is an abstract base class; the CPU must create its own ThreadContext by either deriving from it, or using the templated ProxyThreadContext class.
ProxyThreadContext
The ProxyThreadContext class provides a way to implement a ThreadContext without having to derive from it. ThreadContext is an abstract class, so anything that derives from it and uses its interface will pay the overhead of virtual function calls. This class is created to enable a user-defined Thread object to be used wherever ThreadContexts are used, without paying the overhead of virtual function calls when it is used by itself. The user-defined object must simply provide all the same functions as the normal ThreadContext, and the ProxyThreadContext will forward all calls to the user-defined object. See the code of SimpleThread for an example of using the ProxyThreadContext.
Difference vs. ExecContext
The ThreadContext is slightly different than the ExecContext. The ThreadContext provides access to an individual thread’s state; an ExecContext provides ISA access to the CPU (meaning it is implicitly multithreaded on SMT systems). Additionally the ThreadState is an abstract class that exactly defines the interface; the ExecContext is a more implicit interface that must be implemented so that the ISA can access whatever state it needs. The function calls to access state are slightly different between the two. The ThreadContext provides read/write register methods that take in an architectural register index. The ExecContext provides read/write register methdos that take in a StaticInst and an index, where the index refers to the i’th source or destination register of that StaticInsts. Additionally the ExecContext provides read and write methods to access memory, while the ThreadContext does not provide any methods to access memory.
ThreadState
The ThreadState class is used to hold thread state that is common across CPU models, such as the thread ID, thread status, kernel statistics, memory port pointers, and some statistics of number of instructions completed. Each CPU model can derive from ThreadState and build upon it, adding in thread state that is deemed appropriate. An example of this is SimpleThread, where all of the thread’s architectural state has been added in. However, it is not necessary (or even feasible in some cases) for all of the thread’s state to be centrally located in a ThreadState derived class. The DetailedCPU keeps register values and rename maps in its own classes outside of ThreadState. ThreadState is only used to provide a more convenient way to centrally locate some state, and provide sharing across CPU models.
Faults
Registers
Register types - float, int, misc
Indexing - register spaces stuff
See Register Indexing for a more thorough treatment.
A “nickle tour” of flattening and register indexing in the CPU models.
First, an instruction has identified that it needs register such and such as determined by its encoding (or the fact that it always uses a certain register, or …). For the sake of argument, lets say we’re talking about SPARC, the register is %g1, and the second bank of globals is active. From the instructions point of view, the unflattened register is %g1, which, likely, is just represented by the index 1.
Next, we need to map from the instruction’s view of the register file(s) down to actual storage locations. Think of this like virtual memory. The instruction is working within an index space which is like a virtual address space, and it needs to be mapped down to the flattened space which is like physical memory. Here, the index 1 is likely mapped to, say, 9, where 0-7 is the first bank of globals and 8-15 is the second.
This is the point where the CPU gets involved. The index 9 refers to an actual register the instruction expects to access, and it’s the CPU’s job to make that happen. Before this point, all the work was done by the ISA with no insight available to the CPU, and beyond this point all the work is done by the CPU with no insight available to the ISA.
The CPU is free to provide a register directly like the simple CPU by having an array and just reading and writing the 9th element on behalf of the instruction. The CPU could, alternatively, do something complicated like renaming and mapping the flattened index further into a physical register like O3.
One important property of all this, which makes sense if you think about the virtual memory analogy, is that the size of the index space before flattening has nothing to do with the size after. The virtual memory space could be very large (presumably with gaps) and map to a smaller physical space, or it could be small and map to a larger physical space where the extra is for, say, other virtual spaces used at other times. You need to make sure you’re using the right size (post flattening) to size your tables because that’s the space of possible options.
One other tricky part comes from the fact that we add offsets into the indices to distinguish ints from floats from miscs. Those offsets might be one thing in the preflattening world, but then need to be something else in the post flattening world to keep things from landing on top of each other without leaving gaps. It’s easy to make a mistake here, and it’s one of the reasons I don’t like this offset idea as a way to keep the different types separate. I’d rather see a two dimensional index where the second coordinate was a register type. But in the world as it exists today, this is something you have to keep track of.
PCs
Register Indexing
CPU register indexing in gem5 is a complicated by the need to support multiple ISAs with sometimes very different register semantics (register windows, condition codes, mode-based alternate register sets, etc.). In addition, this support has evolved gradually as new ISAs have been added, so older code may not take advantage of newer features or terminology.
Types of Register Indices
There are three types of register indices used internally in the CPU models: relative, unified, and flattened.
Relative
A relative register index is the index that is encoded in a machine instruction. There is a separate index space for each class of register (integer, floating point, etc.), starting at 0. The register class is implied by the opcode. Thus a value of “1” in a source register field may mean integer register 1 (e.g., “%r1”) or floating point register 1 (e.g., “%f1”) depending on the type of the instruction.
Unified
While relative register indices are good for keeping instruction encodings compact, they are ambiguous, and thus not convenient for things like managing dependencies. To avoid this ambiguity, the decoder maps the relative register indices into a unified register space by adding class-specific offsets to relocate each relative index range into a unique position. Integer registers are unmodified, and continue to start at zero. Floating-point register indices are offset by (at least) the number of integer registers, so that the first FP register (e.g., “%f0”) gets a unified index that is greater than that of the last integer register. Similarly, miscellaneous (a.k.a. control) registers are mapped past the end of the FP register index space.
Flattened
Unified register indices provide an unambiguous description of all the registers that are accessible as instruction operands at a given point in the execution. Unfortunately, due to the complex features of some ISAs, they do not always unambiguously identify the actual state that the instruction is referencing. For example, in ISAs with register windows (notably SPARC), a particular register identifier such as “%o0” will refer to a different register after a “save” or “restore” operation than it did previously. Several ISAs have registers that are hidden in normal operation, but get mapped on top of ordinary registers when an interrupt occurs (e.g., ARM’s mode-specific registers), or under explicit supervisor control (e.g., SPARC’s “alternate globals”).
We solve this problem by maintaining a flattened register space which provides a distinct index for every unique register storage location. For example, the integer portion of the SPARC flattened register space has distinct indices for the globals and the alternate globals, as well as for each of the available register windows. The “flattening” process of translating from a unified or relative register index to a flattened register index varies by ISA. On some ISAs, the mapping is trivial, while others use table lookups to do the translation.
A key distinction between the generation of unified and flattened register indices is that the former can always be done statically while the latter often depends on dynamic processor state. That is, the translation from relative to unified indices depends only on the context provided by the instruction itself (which is convenient as the translation is done in the decoder). In contrast, the mapping to a flattened register index may depend on processor state such as the interrupt level or the current window pointer on SPARC.
Combining Register Index Types
Although the typical progression for modifying register indices is relative -> unified -> flattened, it turns out that relative vs. unified and flattened vs. unflattened are orthogonal attributes. Relative vs. unified indicates whether the index is relative to the base register for its register class (integer, FP, or misc) or has the base offset for its class added in. Flattened vs. unflattened indicates whether the index has been adjusted to account for runtime context such as register window adjustments or alternate register file modes. Thus a relative flattened register index is one in which the runtime context has been accounted for, but is still expressed relative to the base offset for its class.
A single set of class-specific offsets is used to generate unified indices from relative indices regardless of whether the indices are flattened or unflattened. Thus the offsets must be large enough to separate the register classes even when flattened addresses are being used. As a result, the unflattened unified register space is often discontiguous.
Illustrations
As an illustration, consider a hypothetical architecture with four integer registers (%r0-%r4), three FP registers (%f0-%f2), and two misc/control registers (%msr0-%msr1). In addition, the architecture supports a complete set of alternate integer and FP registers for fast context switching.
The resulting register file layout, along with the unified flattened register file indices, is shown at right. Although the indices in the picture range from 0 to 15, the actual set of valid indices depends on the type of index and (for relative indices) the register class as well:
| Relative unflattened | Int: 0-3; FP: 0-2; Misc: 0-1 |
| Unified unflattened | 0-3, 8-10, 14-15 |
| Relative flattened | Int: 0-7; FP: 0-5; Misc: 0-1 |
| Unified flattened | 0-15 |
In this example, register %f1 in the alternate FP register file could be referred to via the relative flattened index 4 as well as the relative unflattened index 1, the unified unflattened index 9, or the unified flattened index 12. Note that the difference between the relative and unified indices is always 8 (regardless of flattening), and the difference between the unflattened and flattened indices is 3 (regardless of relative vs. unified status). 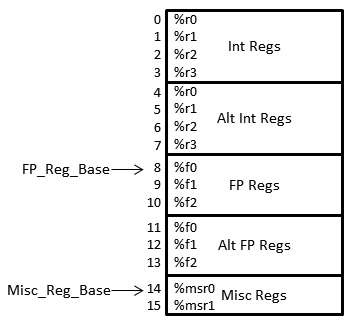
Caveats
- Although the gem5 code is unfortunately not always clear about which type of register index is expected by a particular function, functions whose name incorporates a register class (e.g., readIntReg()) expect a relative register index, and functions that expect a flattened index often have “flat” in the function name.
- Although the general case is complicated, the common case can be deceptively simple. For example, because integer registers start at the beginning of the unified register space, relative and unified register indices are identical for integer registers. Furthermore, in an architecture with no (or rarely-used) alternate integer registers, the unflattened and flattened indices are (almost always) the same as well, meaning that all four types of register indices are interchangeable in this case. While this situation seems to be a simplification, it also tends to hide bugs where the wrong register index type is used.
- The description above is intended to illustrate the typical usage of these index types. There may be exceptions that don’t precisely follow this description, but I got tired of writing “typically” in every sentence.
- The terms ‘relative’ and ‘unified’ were invented for use in this documentation, so you are unlikely see them in the code until the code starts catching up with this page.
- This discussion pertains only to the architectural registers. An out-of-order CPU model such as O3 adds another layer of complexity by renaming these architectural registers (using the flattened register indices) to an underlying physical register file.
ISA and CPU Independence
gem5 tries to keep CPU models ISA independent to make it easier to use any ISA with different CPU models. gem5 relies on two generic interfaces to make this independence possible: static instructions and execution context (both are discussed above). Static instructions allow CPU to manage instructions and the execution context allow ISA or instructions to interact with the CPU. Following picture provides a high level overview of what components in gem5 are ISA dependent or independent:
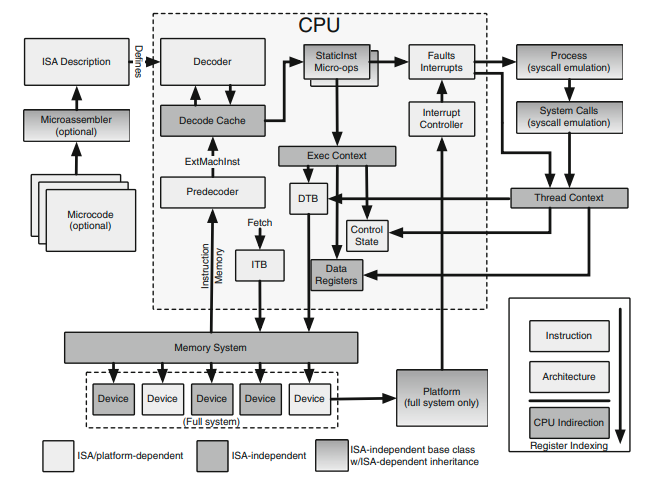
Source of the above figure: Modular ISA-Independent Full-System Simulation (Ch 5 of Processor and System-on-Chip Simulation), G. Black, N. Binkert, and S. Reinhardt, A. Saidi. Link.